
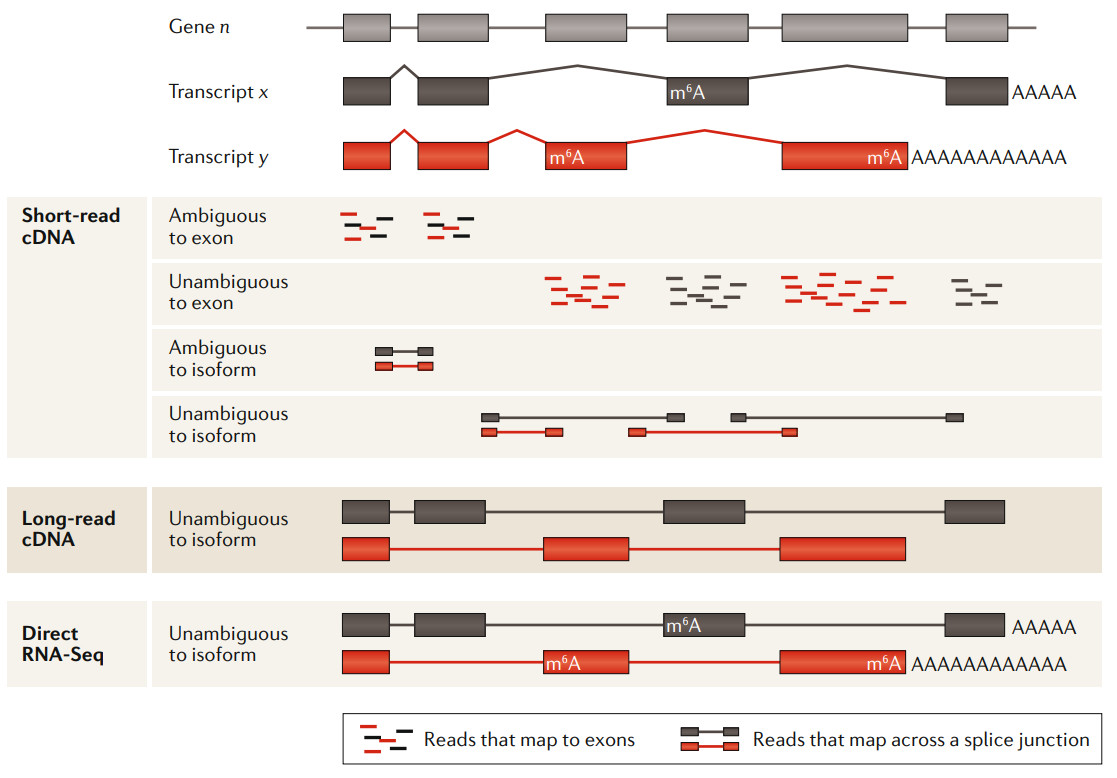
 短读长、长读长与ONT直接RNA测序分析的比较
短读长、长读长与ONT直接RNA测序分析的比较
产品优势
直接RNA测序无需PCR,没有测序GC偏好性
由于PCR 过程具有GC偏好性,对GC含量过高或过低的序列不容易扩增,所以短读长测序在建库和测序过程中都会引入GC偏好,降低了定量分析的准确性。使用ONT测序技术(直接 cDNA & 直接 RNA),无需PCR扩增,提供无偏倚、全长、链特异性的RNA序列。
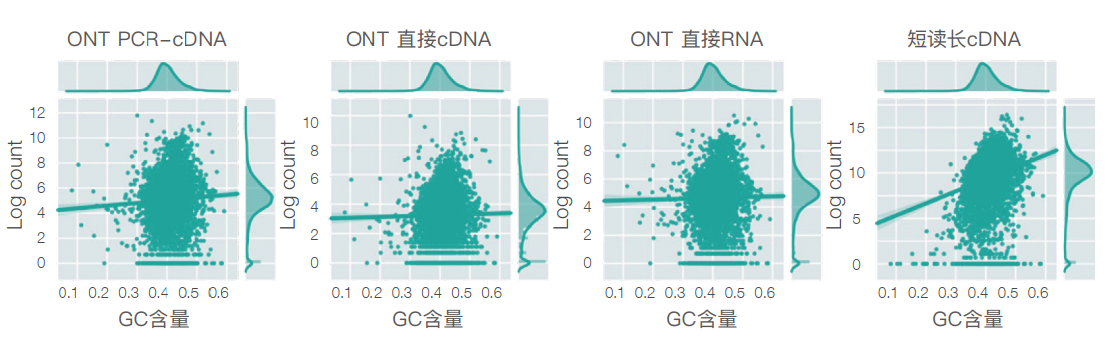 纳米孔数据集里的GC偏倚低于短读长数据集
纳米孔数据集里的GC偏倚低于短读长数据集
准确检测转录本 poly(A)尾长度
转录本 poly(A) 尾被认为在转录后调控中起到重要作用,包括mRNA的稳定性和翻译效率。poly(A)尾长度可达数百个核苷酸,使用短读长测序的数据很难进行测量。ONT直接RNA测序获得的全长转录本包含poly(A)尾信息,利用算法工具计算出poly(A)尾的长度,估算每个读长序列的poly(A)尾长,甚至能够发现异构体间poly(A)尾的区别。
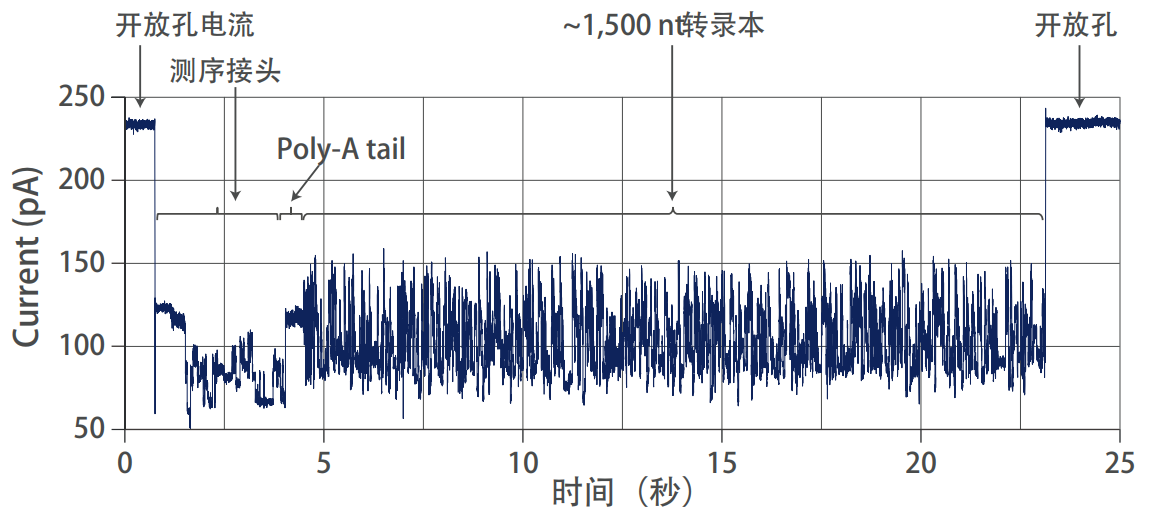 Nanopore 直接 RNA 测序鉴定转录本 poly(A)尾长
Nanopore 直接 RNA 测序鉴定转录本 poly(A)尾长
直接 RNA 测序鉴定 RNA 碱基修饰信息
短读长测序由于在建库过程需要 PCR,从而丢失了 RNA 分子中的碱基修饰信息。直接 RNA 测序不需要扩增或链合成,这意味着在测序过程中,修饰碱基直接穿过纳米孔,在原始信号中产生与未发生修饰的碱基不同的电流特征。通过特定的软件算法对电流特征进行识别,即可鉴定碱基修饰信息。
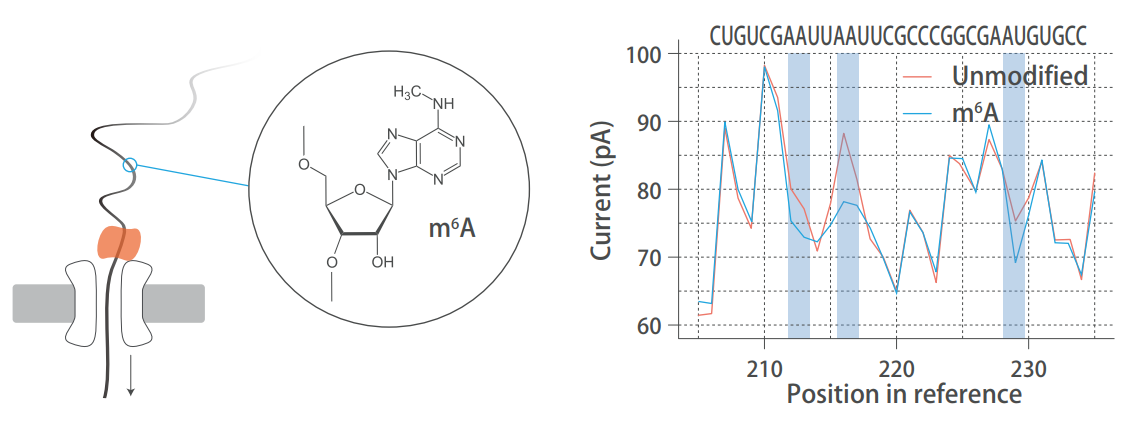 Nanoproe 直接 RNA 测序检测天然 RNA 修饰
Nanoproe 直接 RNA 测序检测天然 RNA 修饰
方案策略
| RNA样本量 | 建库策略 | 测序策略 |
| 总量 ≥ 50 μg, 浓度 ≥180 ng/μL | Direct RNA 1D建库 | 根据研究需求确定 |
分析内容
- 原始数据质控
- RNA碱基修饰检测
- Poly(A)尾长估算
- 参考转录组比对
- 基因功能及转录本结构注释
- 差异基因/转录异构体定量
- 功能富集、蛋白互作分析
结果展示
转录本聚类去冗余
由于同一条转录本在细胞中的一个时间点下可能存在多个拷贝,并且不同的转录本拷贝在测序过程中5’端又可能存在不同程度的降解,所以测序得到的全长reads中,有很多是来源于同一条转录本的冗余序列,需要对全长序列进行聚类去冗余。
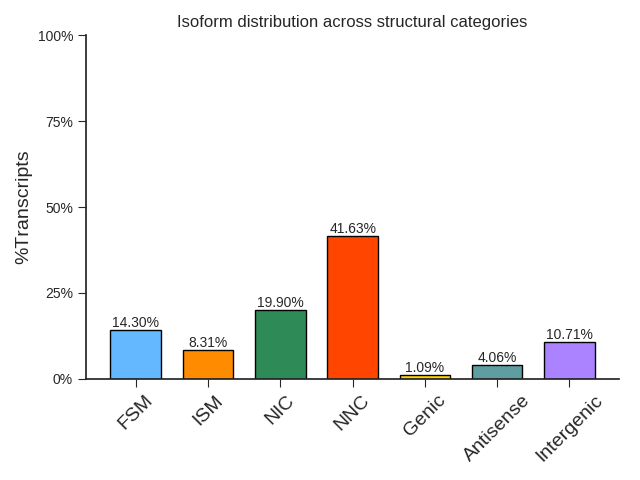 isoform 评估结果
isoform 评估结果
可变剪接识别
可变剪接(Alternative Splice)是调节基因表达和产生蛋白质组多样性的重要机制。
 可变剪接识别
可变剪接识别
Poly(A)尾长度估算
由于direct-RNA测序方式是从RNA 3’端到5’端测序,并且添加poly(T)接头的过程中完整的保存了poly(A)的信息,因此可以从direct-RNA测序的电信号中估算RNA分子的poly(A)尾长度。
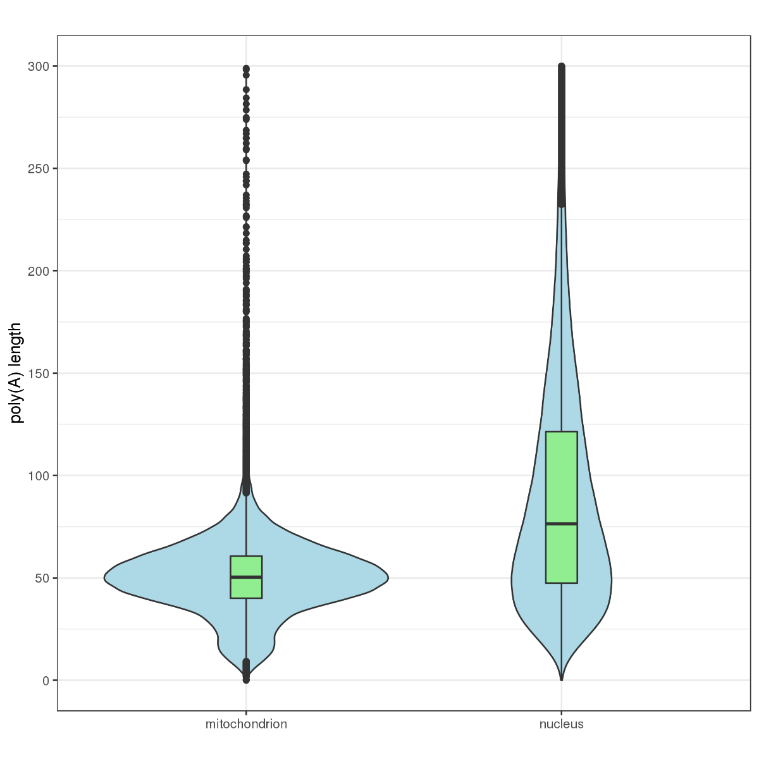 不同基因及转录本的poly(A)尾长度
不同基因及转录本的poly(A)尾长度
RNA甲基化分析
其他测序方式由于在建库测序过程中需要逆转录或者PCR,从而丢失了RNA分子中碱基修饰信息,而direct-RNA测序不需要逆转录或者PCR,意味着在测序过程中,经过表观修饰的碱基可以直接穿过纳米孔,在原始电信号中会产生与未发生修饰的碱基不同的电流特征。通过特定的软件算法对电流特征进行识别,即可鉴定碱基修饰信息。
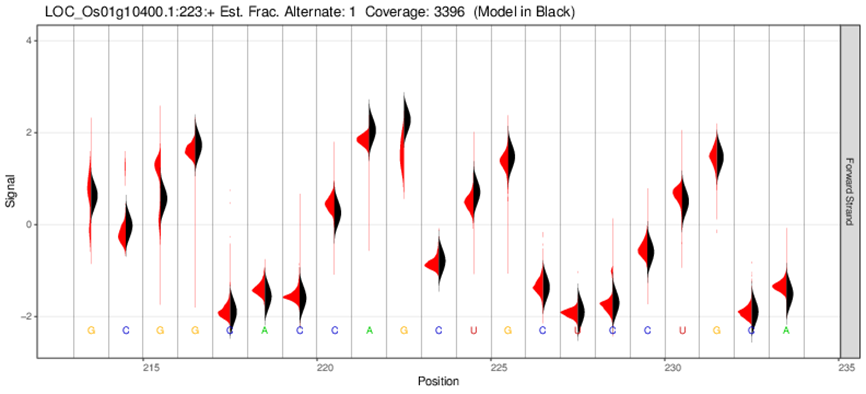 甲基化位点电信号分布图
甲基化位点电信号分布图
常见问题
1. Direct RNA建库 RNA最低起始量需要多少?
质量合格total RNA 40-80ug,浓度 ≥180 ng/μL。
2. Direct RNA 1个cell的产量大约是多少?
因为Direct RNA建库测序没有PCR扩增的过程,相对PCR cDNA全长转录组数据量偏低,高质量total RNA 我们可以承诺数量不低于1Gb。
案例解析
案例分析一
案例解析
Nanopore 直接 RNA 测序人类 poly(A) 转录组
高通量cDNA测序使我们对转录组的复杂性和调控有了更深入的了解,但是该方法不能完全展现转录组的真实信息,其测序读长较短并且去除了天然RNA的碱基修饰信息。本研究利用Nanopore直接RNA测序技术从人类B淋巴细胞系GM12878分离并测序了原始poly(A) RNA,共生成约990万条通过质控的poly(A) RNA序列,读长N50约1,334bp(图1)。
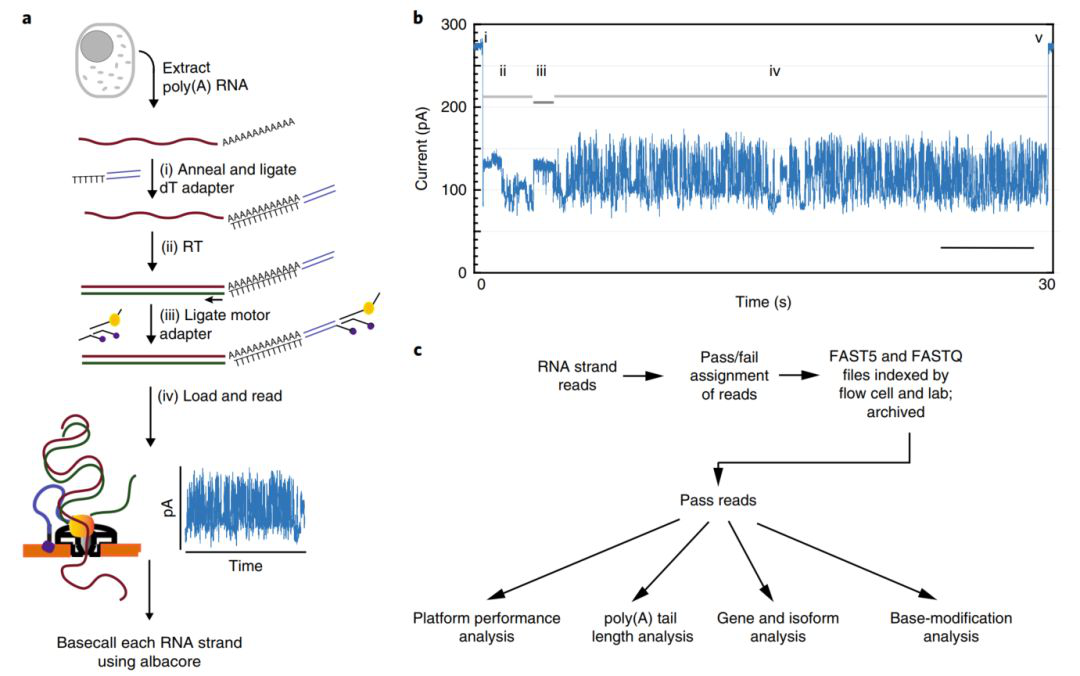 图1 Nanopore 天然 poly(A) RNA测序流程
图1 Nanopore 天然 poly(A) RNA测序流程
长纳米孔读长能够提高外显子-外显子衔接区域的分辨率,从而挖掘未注释的RNA异构体。利用以上长读长数据,研究者首先检测和分析了转录异构体,在代表10,793个基因的33,984个异构体中,发现52.6%未经注释的剪接连接点,识别出了上千个目前在GENCODE v27中未经注释的基因,并发现了使用短读长测序则无法检测到的等位基因特异性异构体。例如:IFIH1基因,其父系同型保留了8号外显子,而母系同型则不保留8号外显子(图2)。
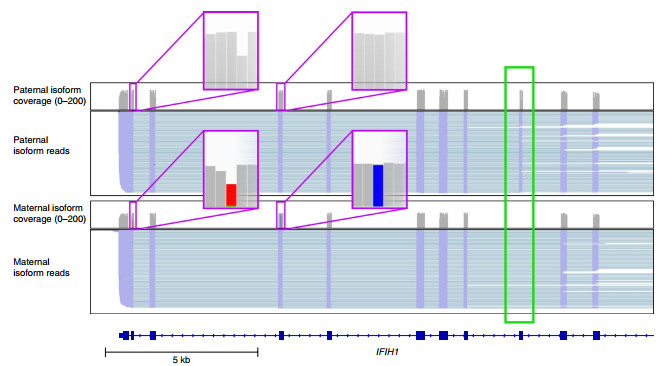 图2 ONT直接RNA测序转录本识别IFIH1的等位基因特异性异构体的IGV视图。紫色方框指示等位基因特异性的snp的位置(灰色为参考,红色和蓝色为SNPs),绿色方框指示可变剪接外显子。
图2 ONT直接RNA测序转录本识别IFIH1的等位基因特异性异构体的IGV视图。紫色方框指示等位基因特异性的snp的位置(灰色为参考,红色和蓝色为SNPs),绿色方框指示可变剪接外显子。
随后结合短读长数据,研究团队直接测量了poly(A)尾长,分析发现了异构体间poly(A)尾的区别。采用ONT直接RNA测序对RNA结合蛋白DEAD-box解旋酶5(DDX5)的转录本poly(A)尾长度进行估计,内含子保留异构体的poly(A)尾长中值为327nt,而其蛋白编码异构体的poly(A)尾长中值为125nt(图3)。
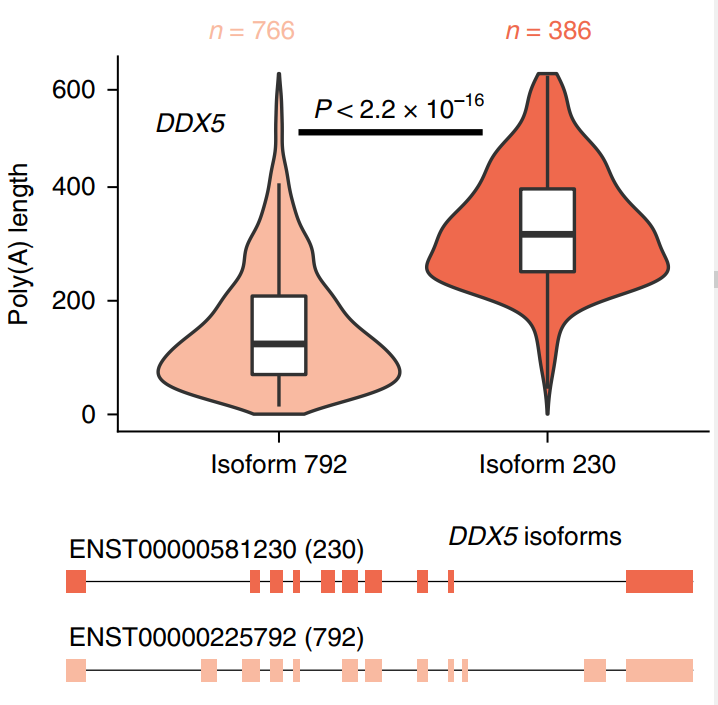 图3 DDX5基因两种转录本异构体的poly(A)尾长分布及基因模型
图3 DDX5基因两种转录本异构体的poly(A)尾长分布及基因模型
最后,利用直接RNA测序数据中包含的RNA修饰信息,研究人员筛选了GENCODE敏感亚型的离子电流在GGACU模体(motif)上的改变,发现了86个基因(198个异构体) 的电流变化可以归因于异构体特异性m6A修饰。
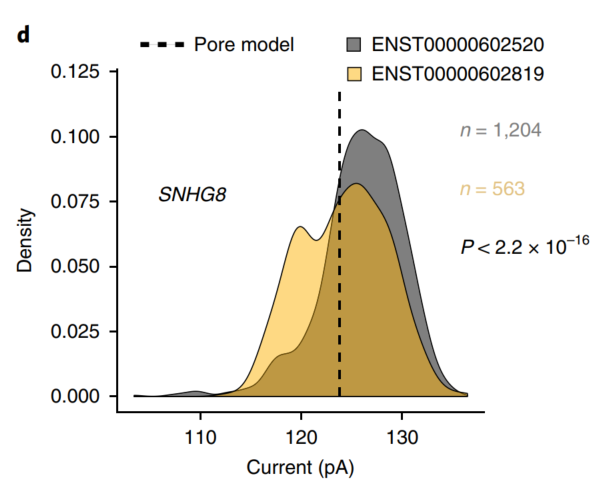 图 4 SNHG8基因异构体内GGACU motif的离子电流分布
图 4 SNHG8基因异构体内GGACU motif的离子电流分布
研究人员表示基于短读长测序的RNA修饰分析去除了修饰之间以及修饰与其他RNA之间的特征,而Nanopore直接RNA测序则具备检测这些远程互作的能力。
参考文献:Workman R E, Tang A D, Tang P S, et al. Nanopore native RNA sequencing of a human poly (A) transcriptome[J]. Nature methods, 2019: 1-9.
官方微信公众号

希望组

希望组科技服务

希望组诊断服务